Women’s Clothing E-Commerce Reviews

Customer reviews provide valuable insight into product quality and opportunities for improvement. This dataset of women’s clothing reviews aims to help the e-commerce company develop a machine learning model that can automatically determine from customer feedback whether a product is recommended or not. With over 23,000 reviews, manually analyzing this volume of feedback is time-consuming and subjective. An automated classification model offers a scalable and consistent approach. However, given the unstructured nature of review text, several techniques must be combined to extract meaningful information for prediction.
We will implement both a bag-of-words model and word embeddings to transform the text into numerical feature vectors. Frequency analysis will identify the most important and least important words for recommendation. Vectorization using TF-IDF and binarization will convert words into vector representations.
Multiple machine learning algorithms will be tested to find the highest accuracy model for determining product recommendation. Metrics like precision, recall, and F1 score will also be considered in model selection.
The chosen model will provide the company insight into which review aspects most correlate with positive or negative recommendations. With a trained model, new reviews can be automatically classified to inform inventory and merchandising decisions for improved customer satisfaction.
The techniques demonstrated here for analyzing customer reviews can be generalized to other industries reliant on customer feedback to optimize products and drive business value.
Model 1: Bag Of Words
Load the data into memory and clean the messages
filename = r'Womens Clothing E-Commerce Reviews.csv'
WomensClothing= pd.read_csv(filename,encoding='latin-1')
WomensClothing.head(5)
| Clothing ID | Age | Title | Review Text | Rating | Recommended IND | Positive Feedback Count | Division Name | Department Name | Class Name | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 767 | 33 | NaN | Absolutely wonderful - silky and sexy and comf... | 4 | 1 | 0 | Initmates | Intimate | Intimates |
| 1 | 1080 | 34 | NaN | Love this dress! it's sooo pretty. i happene... | 5 | 1 | 4 | General | Dresses | Dresses |
| 2 | 1077 | 60 | Some major design flaws | I had such high hopes for this dress and reall... | 3 | 0 | 0 | General | Dresses | Dresses |
| 3 | 1049 | 50 | My favorite buy! | I love, love, love this jumpsuit. it's fun, fl... | 5 | 1 | 0 | General Petite | Bottoms | Pants |
| 4 | 847 | 47 | Flattering shirt | This shirt is very flattering to all due to th... | 5 | 1 | 6 | General | Tops | Blouses |
WomensClothing['Review Text'] = WomensClothing['Review Text'].astype(str)
Recommended_IND = WomensClothing[['Review Text', 'Recommended IND']]
import seaborn as sns
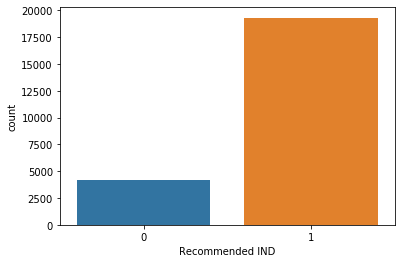
WomensClothing.groupby('Recommended IND')['Recommended IND'].count()
sns.countplot(x='Recommended IND', data=WomensClothing)
features = WomensClothing['Review Text'].astype(str)
labels = WomensClothing['Recommended IND']
print(features)
print(labels)
0 Absolutely wonderful - silky and sexy and comf...
1 Love this dress! it's sooo pretty. i happene...
2 I had such high hopes for this dress and reall...
3 I love, love, love this jumpsuit. it's fun, fl...
4 This shirt is very flattering to all due to th...
...
23481 I was very happy to snag this dress at such a ...
23482 It reminds me of maternity clothes. soft, stre...
23483 This fit well, but the top was very see throug...
23484 I bought this dress for a wedding i have this ...
23485 This dress in a lovely platinum is feminine an...
Name: Review Text, Length: 23486, dtype: object
0 1
1 1
2 0
3 1
4 1
..
23481 1
23482 1
23483 0
23484 1
23485 1
Name: Recommended IND, Length: 23486, dtype: int64
def clean_One_Twit(doc):
tokens = doc.split()
re_punc = re.compile('[%s]' % re.escape(string.punctuation))
tokens = [re_punc.sub('', w) for w in tokens]
tokens = [word for word in tokens if word.isalpha()]
stop_words = set(stopwords.words('english'))
tokens = [w for w in tokens if not w in stop_words]
tokens = [word for word in tokens if len(word) > 1]
porter = PorterStemmer()
stemmed = [porter.stem(word) for word in tokens]
return stemmed
vocab = Counter()
for index, row in Recommended_IND.iterrows():
if index % 10000 ==0:
print(index)
text = row['Review Text']
tokens = clean_One_Twit(text)
vocab.update(tokens)
print(len(vocab))
print(vocab.most_common(50))
min_occurrence = 10
minvocab = [k for k,c in vocab.items() if c >= min_occurrence]
print(len(minvocab))
0
10000
20000
13832
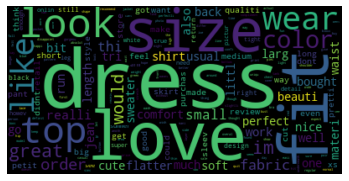
[('dress', 12061), ('love', 11350), ('fit', 11310), ('size', 10597), ('look', 9276), ('top', 8261), ('wear', 8047), ('like', 7717), ('color', 7191), ('great', 6077), ('im', 5512), ('would', 5010), ('order', 4983), ('fabric', 4852), ('small', 4564), ('thi', 4334), ('realli', 3921), ('perfect', 3808), ('nice', 3800), ('littl', 3773), ('one', 3694), ('flatter', 3649), ('tri', 3623), ('beauti', 3464), ('soft', 3369), ('comfort', 3277), ('well', 3237), ('back', 3180), ('cute', 3024), ('bought', 2981), ('usual', 2886), ('bit', 2874), ('work', 2858), ('materi', 2816), ('shirt', 2793), ('larg', 2791), ('run', 2777), ('much', 2702), ('sweater', 2689), ('length', 2629), ('jean', 2593), ('also', 2575), ('go', 2539), ('waist', 2509), ('petit', 2438), ('got', 2411), ('think', 2410), ('long', 2392), ('short', 2369), ('make', 2344)]
2570
Create and generate a word cloud image
wordcloud = WordCloud().generate_from_frequencies(frequencies=vocab)
# Display the generated image:
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
def doc_to_line(oneTwit, vocab):
tokens = clean_One_Twit(oneTwit)
tokens = [w for w in tokens if w in vocab]
return ' '.join(tokens)
lines = list()
for index, row in Recommended_IND.iterrows():
if index % 10000 ==0:
print(index)
text = row['Review Text']
line = doc_to_line(text, minvocab)
lines.append(line)
print(len(lines))
print(lines[5])
0
10000
20000
23486
love traci rees dress one petit feet tall usual wear brand dress pretti packag lot dress skirt long full overwhelm small frame stranger alter shorten narrow skirt would take away embellish garment love color idea style work return dress
def create_tokenizer(lines):
tokenizer = Tokenizer()
tokenizer.fit_on_texts(lines)
return tokenizer
tokenizer = create_tokenizer(lines)
Xtrain = tokenizer.texts_to_matrix(lines, mode='freq')
print(Xtrain.shape)
n_words = Xtrain.shape[1]
print(n_words)
(23486, 2566)
2566
def evaluate_mode(Xtrain, ytrain, Xtest, ytest):
scores = list()
n_repeats = 1
n_words = Xtest.shape[1]
for i in range(n_repeats):
# define network
model = Sequential()
model.add(Dense(50, input_shape=(n_words,), activation='relu'))
model.add(Dense(2, activation='softmax'))
# compile network
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit network on the training dataset
model.fit(Xtrain, ytrain, epochs=100, verbose=0)
# evaluate the model on the unseen test dataset
val_loss, val_acc = model.evaluate(Xtest, ytest, verbose=0)
scores.append(val_acc)
print('%d accuracy: %s' % ((i+1), val_acc))
return scores
labels = pd.get_dummies(labels)
X_train, X_test, y_train, y_test = train_test_split(Xtrain, labels,
test_size=.20,
random_state=2020,
stratify=labels)
modes = ['binary', 'count', 'tfidf', 'freq']
results = DataFrame()
for mode in modes:
# evaluate model on data for mode
results[mode] = evaluate_mode(X_train, y_train, X_test, y_test)
# summarize results
print(results.describe())
1 accuracy: 0.8676032354700763
1 accuracy: 0.8656875264548199
1 accuracy: 0.8690932312129457
1 accuracy: 0.8729246486598454
binary count tfidf freq
count 1.000000 1.000000 1.000000 1.000000
mean 0.867603 0.865688 0.869093 0.872925
std NaN NaN NaN NaN
min 0.867603 0.865688 0.869093 0.872925
25% 0.867603 0.865688 0.869093 0.872925
50% 0.867603 0.865688 0.869093 0.872925
75% 0.867603 0.865688 0.869093 0.872925
max 0.867603 0.865688 0.869093 0.872925
Word Emmbading
filename = r'Womens Clothing E-Commerce Reviews.csv'
WomensClothing= pd.read_csv(filename,encoding='latin-1')
WomensClothing['Review Text'] = WomensClothing['Review Text'].astype(str)
train, test = train_test_split(WomensClothing, test_size=0.20, random_state=2019, stratify = WomensClothing[['Recommended IND']])
labels = train['Recommended IND']
str(train)
' Clothing ID Age Title \\\n18342 1092 43 Light weight, pockets, great for summer \n512 1078 49 Cute but skip the petite unless you are very s... \n8334 1047 38 Perfect \n22294 1077 58 Love it! \n2883 829 69 Love it \n... ... ... ... \n5714 880 39 NaN \n22500 1098 57 Embroidered masterpiece \n16279 1078 38 Gorgeous dress - spectacular! \n18535 24 29 Super unflattering \n17363 912 51 Lint magnet \n\n Review Text Rating \\\n18342 I run 170lbs., 36 d, 5\'4" and ordered a regula... 5 \n512 Beautiful colors, especially the pink. i am 5\'... 5 \n8334 I love these pants! waited for them to go on s... 5 \n22294 I would absolutely recommend this dress if you... 4 \n2883 I love this top! i was thinking that i was goi... 5 \n... ... ... \n5714 This shirt runs extremely large. looks boxy an... 3 \n22500 This dress is so beautifully embroidered with ... 5 \n16279 This dress is a beauty. i am 5\'11" and plan to... 5 \n18535 I\'m 5\' 5", 150 lbs, 32dd, normally a 28p or 29... 2 \n17363 So sad becuase i like the design. i would not ... 2 \n\n Recommended IND Positive Feedback Count Division Name \\\n18342 1 13 General Petite \n512 1 3 General \n8334 1 0 General Petite \n22294 1 0 General Petite \n2883 1 1 General Petite \n... ... ... ... \n5714 0 0 General \n22500 1 1 General \n16279 1 0 General Petite \n18535 0 0 Initmates \n17363 0 2 General \n\n Department Name Class Name \n18342 Dresses Dresses \n512 Dresses Dresses \n8334 Bottoms Pants \n22294 Dresses Dresses \n2883 Tops Blouses \n... ... ... \n5714 Tops Knits \n22500 Dresses Dresses \n16279 Dresses Dresses \n18535 Intimate Swim \n17363 Tops Fine gauge \n\n[18788 rows x 10 columns]'
vocab_size = 10000
encoded_docs=[]
index = 1
for index, row in train.iterrows():
if index % 10000 ==0:
print(index)
# take out the esentiment text
text = row['Review Text']
encoded_docs.append(one_hot(text, vocab_size))
20000
max_length = len(max(encoded_docs,key=len))
max_length
#make sure all the items have the uniform length
padded_docs = pad_sequences(encoded_docs, maxlen=max_length, padding='post')
print(padded_docs)
[[7953 4197 534 ... 0 0 0]
[3421 2002 5064 ... 0 0 0]
[7953 9119 4448 ... 0 0 0]
...
[2735 8635 6907 ... 0 0 0]
[1409 8101 3212 ... 0 0 0]
[4747 6127 5164 ... 0 0 0]]
epoch=10
model = Sequential()
#specify the vocab size, dimensionality of the word embedding spaces
model.add(Embedding(vocab_size, 50, input_length=max_length))
#then we map the matrices to one-dimensional vector by calling flatten() funciton
model.add(Flatten())
#binary classifiction, 1 neuron, activation sigmoid; produce probablity
model.add(Dense(1, activation='sigmoid'))
# compile the model
#binary classifiction, loss = 'binary_crossentropy'
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc'])
# summarize the model
model.summary()
# fit the model
#1st argument is the features/predictors/Xs; 2nd is the label/target/Ys
#ecpochs: pass the whole data to the Neural net work for 50 times
#verbose = 0; don't print anything
#verbose = 1; print key outputs
#vervose = 2; print all the info
model.fit(padded_docs, labels, epochs=epoch, verbose=2)
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_2 (Embedding) (None, 116, 50) 500000
_________________________________________________________________
flatten_2 (Flatten) (None, 5800) 0
_________________________________________________________________
dense_2 (Dense) (None, 1) 5801
=================================================================
Total params: 505,801
Trainable params: 505,801
Non-trainable params: 0
_________________________________________________________________
Epoch 1/10
- 4s - loss: 0.3536 - acc: 0.8520
Epoch 2/10
- 4s - loss: 0.2207 - acc: 0.9098
Epoch 3/10
- 4s - loss: 0.1609 - acc: 0.9403
Epoch 4/10
- 4s - loss: 0.1067 - acc: 0.9682
Epoch 5/10
- 4s - loss: 0.0670 - acc: 0.9842
Epoch 6/10
- 4s - loss: 0.0441 - acc: 0.9916
Epoch 7/10
- 4s - loss: 0.0313 - acc: 0.9944
Epoch 8/10
- 4s - loss: 0.0239 - acc: 0.9956
Epoch 9/10
- 4s - loss: 0.0192 - acc: 0.9964
Epoch 10/10
- 4s - loss: 0.0166 - acc: 0.9964
encoded_docs_test=[]
for index, row in test.iterrows():
if index % 10000 ==0:
print(index)
text = row['Review Text']
encoded_docs_test.append(one_hot(text, vocab_size))
0
10000
padded_docs_test = pad_sequences(encoded_docs_test, maxlen=max_length, padding='post')
print(padded_docs_test)
labels_test = test['Recommended IND']
loss, accuracy = model.evaluate(padded_docs_test, labels_test, verbose=2)
print('Accuracy: %f' % (accuracy*100))
[[2735 6907 2673 ... 0 0 0]
[ 421 4475 8879 ... 0 0 0]
[7325 2735 8635 ... 0 0 0]
...
[7953 9119 2735 ... 0 0 0]
[1344 6867 7953 ... 0 0 0]
[7953 7574 8879 ... 0 0 0]]
Accuracy: 89.016603
After the training, testing splitting, and the cleaning of the Reviews text. The accuracy of the model that came as the main resultant output of the first part. It states the accuracy of each model and the analytics of each mathematical computation for the data of the Bag of Words models, such as the mean and standard deviation. Based on the accuracy, the best model is the Word Embedding model with 89% accuracy.
Model 2
The second part of the project is to build a machine learning model to forecast the rating of the products from the reviews written by the customers as the review text. Several models can be built for this purpose to forecast Rating using Reviews Text.
Bag of Words
WomensClothing = WomensClothing.replace(0, numpy.NaN)
WomensClothing.dropna(inplace=True)
print(WomensClothing.shape)
(8572, 10)
The goal of the project is to forecast the best model for the management that shall predict the rating. To achieve this goal, we take the rating column as labels. Then those labels are passed as testing of the model to predict the accuracy of the model.
features = WomensClothing['Review Text'].astype(str)
labels = WomensClothing['Rating']
import seaborn as sns
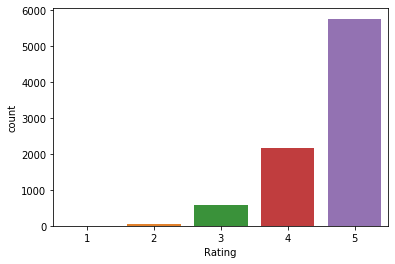
WomensClothing.groupby('Rating')['Rating'].count()
sns.countplot(x='Rating', data=WomensClothing)
def clean_One_Twit(doc):
tokens = doc.split()
re_punc = re.compile('[%s]' % re.escape(string.punctuation))
tokens = [re_punc.sub('', w) for w in tokens]
tokens = [word for word in tokens if word.isalpha()]
stop_words = set(stopwords.words('english'))
tokens = [w for w in tokens if not w in stop_words]
tokens = [word for word in tokens if len(word) > 1]
porter = PorterStemmer()
stemmed = [porter.stem(word) for word in tokens]
return stemmed
vocab = Counter()
for index, row in WomensClothing.iterrows():
if index % 10000 ==0:
print(index)
text = row['Review Text']
tokens = clean_One_Twit(text)
vocab.update(tokens)
print(len(vocab))
print(vocab.most_common(50))
min_occurrence = 10
minvocab = [k for k,c in vocab.items() if c >= min_occurrence]
print(len(minvocab))
20000
8853
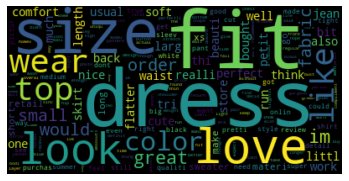
[('dress', 5041), ('fit', 4961), ('size', 4766), ('love', 4579), ('look', 3609), ('wear', 3447), ('top', 3409), ('like', 3091), ('color', 3012), ('great', 2423), ('im', 2413), ('order', 2037), ('would', 1986), ('fabric', 1970), ('small', 1904), ('perfect', 1731), ('thi', 1705), ('littl', 1695), ('nice', 1688), ('tri', 1624), ('flatter', 1623), ('realli', 1620), ('one', 1581), ('soft', 1470), ('beauti', 1404), ('usual', 1380), ('comfort', 1377), ('well', 1376), ('bit', 1314), ('bought', 1281), ('petit', 1260), ('length', 1207), ('jean', 1167), ('back', 1157), ('cute', 1157), ('run', 1154), ('waist', 1153), ('larg', 1130), ('think', 1091), ('work', 1090), ('also', 1042), ('skirt', 1038), ('store', 1035), ('much', 1035), ('sweater', 1034), ('long', 1028), ('materi', 1012), ('retail', 995), ('go', 992), ('make', 988)]
1774
Create and generate a word cloud image
wordcloud = WordCloud().generate_from_frequencies(frequencies=vocab)
# Display the generated image:
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
def doc_to_line(oneTwit, vocab):
tokens = clean_One_Twit(oneTwit)
tokens = [w for w in tokens if w in vocab]
return ' '.join(tokens)
lines = list()
for index, row in WomensClothing.iterrows():
if index % 10000 ==0:
print(index)
text = row['Review Text']
line = doc_to_line(text, minvocab)
lines.append(line)
print(len(lines))
20000
8572
def create_tokenizer(lines):
tokenizer = Tokenizer()
tokenizer.fit_on_texts(lines)
return tokenizer
tokenizer = create_tokenizer(lines)
Xtrain = tokenizer.texts_to_matrix(lines, mode='freq')
print(Xtrain.shape)
n_words = Xtrain.shape[1]
print(n_words)
(8572, 1772)
1772
def evaluate_mode(Xtrain, ytrain, Xtest, ytest):
scores = list()
n_repeats = 1
n_words = Xtest.shape[1]
for i in range(n_repeats):
# define network
model = Sequential()
model.add(Dense(50, input_shape=(n_words,), activation='relu'))
model.add(Dense(6, activation='softmax'))
# compile network
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit network on the training dataset
model.fit(Xtrain, ytrain, epochs=100, verbose=0)
# evaluate the model on the unseen test dataset
val_loss, val_acc = model.evaluate(Xtest, ytest, verbose=0)
scores.append(val_acc)
print('%d accuracy: %s' % ((i+1), val_acc))
return scores
X_train, X_test, y_train, y_test = train_test_split(Xtrain, labels,
test_size=.20,
random_state=2020,
stratify=labels)
modes = ['binary', 'count', 'tfidf', 'freq']
results = DataFrame()
for mode in modes:
# evaluate model on data for mode
results[mode] = evaluate_mode(X_train, y_train, X_test, y_test)
# summarize results
print(results.describe())
1 accuracy: 0.6588921284015256
1 accuracy: 0.6728862974977354
1 accuracy: 0.6483965016662553
1 accuracy: 0.6612244899175606
binary count tfidf freq
count 1.000000 1.000000 1.000000 1.000000
mean 0.658892 0.672886 0.648397 0.661224
std NaN NaN NaN NaN
min 0.658892 0.672886 0.648397 0.661224
25% 0.658892 0.672886 0.648397 0.661224
50% 0.658892 0.672886 0.648397 0.661224
75% 0.658892 0.672886 0.648397 0.661224
max 0.658892 0.672886 0.648397 0.661224
Word Emmbading
WomensClothing['Review Text'] = WomensClothing['Review Text'].astype(str)
train, test = train_test_split(WomensClothing, test_size=0.20, random_state=2019, stratify = WomensClothing[['Rating']])
labels = train['Rating']
str(train)
' Clothing ID Age Title \\\n12302 509 69 Juneberry sleep pants perfect fit \n13962 1098 31 High quality one of a kind piece \n5731 868 30 NaN \n10224 147 46 NaN \n7366 965 27 Cute but poor quality \n... ... ... ... \n22578 1070 58 Perfect! \n18634 1072 36 Shape odd \n18800 1047 53 NaN \n16841 1104 29 Buy if you have no fat \n18484 1080 39 Gorgeous print \n\n Review Text Rating \\\n12302 I love these sleep pants they are the perfect ... 5 \n13962 This dress had my attention immediately online... 5 \n5731 Great shirt, more of a stretch to it than i th... 5 \n10224 nan 5 \n7366 This sweater/jacket looks just like the photo ... 2 \n... ... ... \n22578 When i saw these in the store i liked how they... 5 \n18634 The shape was not as nice on model, seemed lik... 3 \n18800 Purchased these in the blue motif. love the he... 5 \n16841 Although i am small (size xs on top, 27 waist)... 3 \n18484 I was thinking this was another maeve winner b... 5 \n\n Recommended IND Positive Feedback Count Division Name Department Name \\\n12302 1 0 Initmates Intimate \n13962 1 2 General Dresses \n5731 1 0 General Tops \n10224 1 0 Initmates Intimate \n7366 0 2 General Jackets \n... ... ... ... ... \n22578 1 0 General Bottoms \n18634 0 1 General Dresses \n18800 1 0 General Bottoms \n16841 0 0 General Dresses \n18484 1 7 General Dresses \n\n Class Name \n12302 Sleep \n13962 Dresses \n5731 Knits \n10224 Sleep \n7366 Jackets \n... ... \n22578 Pants \n18634 Dresses \n18800 Pants \n16841 Dresses \n18484 Dresses \n\n[18788 rows x 10 columns]'
vocab_size = 10000
encoded_docs=[]
for index, row in train.iterrows():
if index % 10000 ==0:
print(index)
text = row['Review Text']
encoded_docs.append(one_hot(text, vocab_size))
0
20000
max_length = len(max(encoded_docs,key=len))
max_length
padded_docs = pad_sequences(encoded_docs, maxlen=max_length, padding='post')
print(padded_docs)
len(padded_docs)
[[1262 7890 2444 ... 0 0 0]
[ 998 6161 2689 ... 0 0 0]
[3857 7395 502 ... 0 0 0]
...
[9632 2444 7364 ... 0 0 0]
[ 409 1262 9513 ... 0 0 0]
[1262 237 832 ... 0 0 0]]
18788
model = Sequential()
model.add(Embedding(vocab_size, 50, input_length=max_length))
model.add(Flatten())
model.add(Dense(6, activation='softmax'))
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['acc'])
model.summary()
model.fit(padded_docs, labels, epochs=10, verbose=2)
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 116, 50) 500000
_________________________________________________________________
flatten_1 (Flatten) (None, 5800) 0
_________________________________________________________________
dense_1 (Dense) (None, 6) 34806
=================================================================
Total params: 534,806
Trainable params: 534,806
Non-trainable params: 0
_________________________________________________________________
Epoch 1/10
- 4s - loss: 1.0535 - acc: 0.5863
Epoch 2/10
- 4s - loss: 0.7825 - acc: 0.6836
Epoch 3/10
- 4s - loss: 0.5838 - acc: 0.7966
Epoch 4/10
- 4s - loss: 0.4007 - acc: 0.8841
Epoch 5/10
- 4s - loss: 0.2705 - acc: 0.9341
Epoch 6/10
- 4s - loss: 0.1872 - acc: 0.9602
Epoch 7/10
- 4s - loss: 0.1351 - acc: 0.9727
Epoch 8/10
- 4s - loss: 0.0993 - acc: 0.9806
Epoch 9/10
- 4s - loss: 0.0778 - acc: 0.9842
Epoch 10/10
- 4s - loss: 0.0629 - acc: 0.9869
encoded_docs_test=[]
for index, row in test.iterrows():
if index % 10000 ==0:
print(index)
text = row['Review Text']
encoded_docs_test.append(one_hot(text, vocab_size))
10000
padded_docs_test = pad_sequences(encoded_docs_test, maxlen=max_length, padding='post')
print(padded_docs_test)
labels_test = test['Rating']
loss, accuracy = model.evaluate(padded_docs_test, labels_test, verbose=2)
print('Accuracy: %f' % (accuracy*100))
[[3857 6716 8953 ... 0 0 0]
[9695 8550 1499 ... 0 0 0]
[1262 7550 998 ... 0 0 0]
...
[ 998 9914 3522 ... 0 0 0]
[2444 3728 502 ... 0 0 0]
[9695 3522 3671 ... 0 0 0]]
Accuracy: 60.323542
After the training, testing splitting, and the cleaning of the Reviews text. We passed the data through the 4 mentioned BOW models plus the Word Embedding model. Based on the accuracy, the model that gave the best efficiency was the Count model, which gave the highest accuracy among the rest as 67%.
