Sentiment Analysis Web App

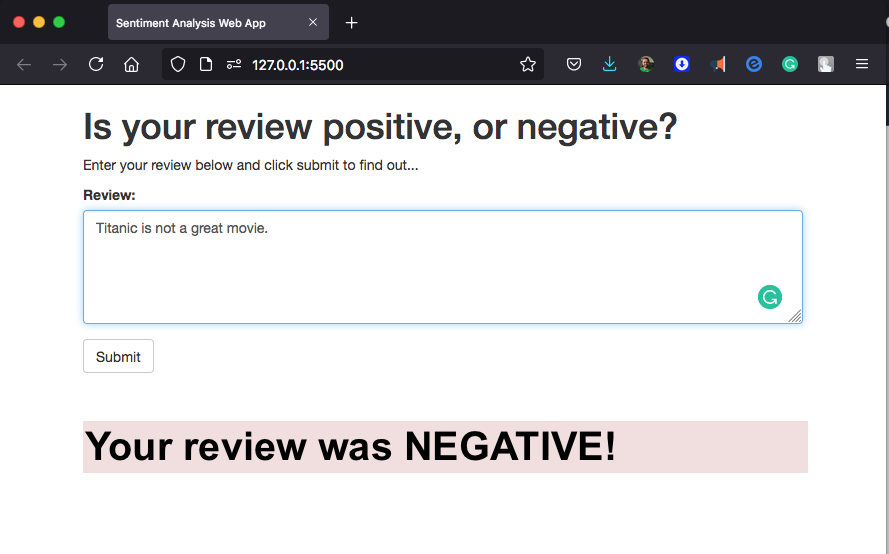
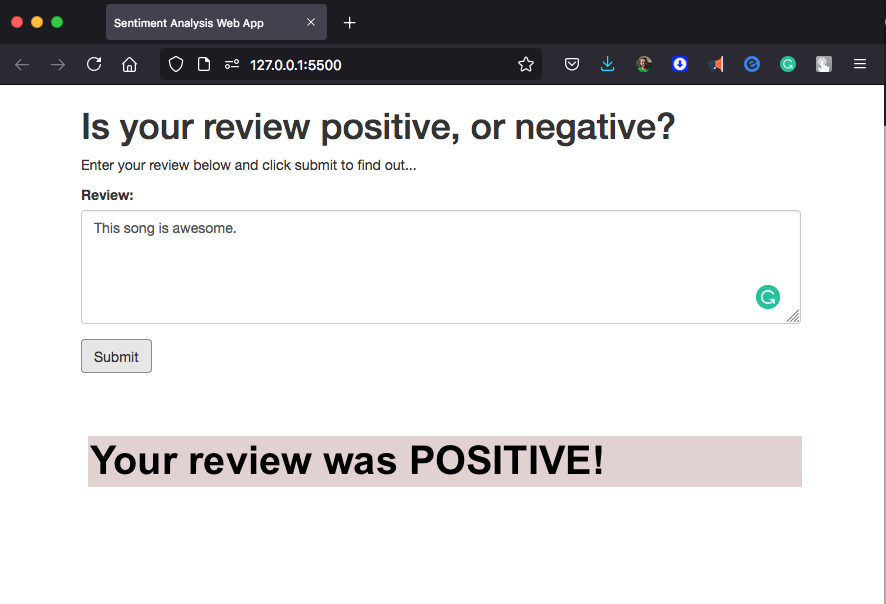
In this project we will construct a recurrent neural network for the purpose of determining the sentiment of a movie review using the IMDB data set. We will create this model using Amazon’s SageMaker service. In addition, We will deploy our model and construct a simple web app which will interact with the deployed model.
General Outline
Recall the general outline for SageMaker projects using a notebook instance.
- Step 1: Download or otherwise retrieve the data.
- Step 2: Process / Prepare the data.
- Step 3: Upload the processed data to S3.
- Step 4: Train a chosen model.
- Step 5: Test the trained model (typically using a batch transform job).
- Step 6: Deploy the trained model.
- Step 7: Use the deployed model.
For this project, we will be following the steps in the general outline with some modifications.
First, we will not be testing the model in its own step. We will still be testing the model, however, we will do it by deploying our model and then using the deployed model by sending the test data to it. One of the reasons for doing this is so that we can make sure that our deployed model is working correctly before moving forward.
In addition, we will deploy and use our trained model a second time. In the second iteration we will customize the way that our trained model is deployed by including some of our own code. In addition, our newly deployed model will be used in the sentiment analysis web app.
Step 1: Downloading the data
As in the XGBoost in SageMaker notebook, we will be using the IMDb dataset
%mkdir ../data
!wget -O ../data/aclImdb_v1.tar.gz http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
!tar -zxf ../data/aclImdb_v1.tar.gz -C ../data
Step 2: Preparing and Processing the data
Also, as in the XGBoost notebook, we will be doing some initial data processing. To begin with, we will read in each of the reviews and combine them into a single input structure. Then, we will split the dataset into a training set and a testing set.
data, labels = read_imdb_data()
print("IMDB reviews: train = {} pos / {} neg, test = {} pos / {} neg".format(
len(data['train']['pos']), len(data['train']['neg']),
len(data['test']['pos']), len(data['test']['neg'])))
IMDB reviews: train = 12500 pos / 12500 neg, test = 12500 pos / 12500 neg
Now that we’ve read the raw training and testing data from the downloaded dataset, we will combine the positive and negative reviews and shuffle the resulting records.
train_X, test_X, train_y, test_y = prepare_imdb_data(data, labels)
print("IMDb reviews (combined): train = {}, test = {}".format(len(train_X), len(test_X)))
IMDb reviews (combined): train = 25000, test = 25000
Now that we have our training and testing sets unified and prepared, we should do a quick check and see an example of the data our model will be trained on. This is generally a good idea as it allows us to see how each of the further processing steps affects the reviews and it also ensures that the data has been loaded correctly.
print(train_X[100])
print(train_y[100])
One of Frances Farmer's earliest movies; at 22, she is absolutely beautiful. Bing Crosby is in great voice, but the songs are not his best. Martha Raye and Bob Burns are interesting, but their comedy, probably great in its time, is really corny today. Roy Rogers also appears- in a singing role. In my view only worth watching if you are a Frances Farmer fan, and possibly a Bing Crosby fan.
0
The first step in processing the reviews is to make sure that any html tags that appear should be removed. In addition we wish to tokenize our input, that way words such as entertained and entertaining are considered the same with regard to sentiment analysis.
The review_to_words method defined above uses BeautifulSoup to remove any html tags that appear and uses the nltk package to tokenize the reviews. Also, this method convert to lower letters, split string into words, remove stopwords and stem the words, remove punctuation marks.
# TODO: Apply review_to_words to a review (train_X[100] or any other review)
review_to_words(train_X[100])
['one',
'franc',
'farmer',
'earliest',
'movi',
'22',
'absolut',
'beauti',
'bing',
'crosbi',
'great',
'voic',
'song',
'best',
'martha',
'ray',
'bob',
'burn',
'interest',
'comedi',
'probabl',
'great',
'time',
'realli',
'corni',
'today',
'roy',
'roger',
'also',
'appear',
'sing',
'role',
'view',
'worth',
'watch',
'franc',
'farmer',
'fan',
'possibl',
'bing',
'crosbi',
'fan']
The method below applies the review_to_words method to each of the reviews in the training and testing datasets. In addition it caches the results. This is because performing this processing step can take a long time. This way if we are unable to complete the notebook in the current session, we can come back without needing to process the data a second time.
# Preprocess data
train_X, test_X, train_y, test_y = preprocess_data(train_X, test_X, train_y, test_y)
Wrote preprocessed data to cache file: preprocessed_data.pkl
Transform the data
In the XGBoost notebook we transformed the data from its word representation to a bag-of-words feature representation. For the model we are going to construct in this notebook we will construct a feature representation which is very similar. To start, we will represent each word as an integer. Of course, some of the words that appear in the reviews occur very infrequently and so likely don’t contain much information for the purposes of sentiment analysis. The way we will deal with this problem is that we will fix the size of our working vocabulary and we will only include the words that appear most frequently. We will then combine all of the infrequent words into a single category and, in our case, we will label it as 1.
Since we will be using a recurrent neural network, it will be convenient if the length of each review is the same. To do this, we will fix a size for our reviews and then pad short reviews with the category ‘no word’ (which we will label 0) and truncate long reviews.
Create a word dictionary
To begin with, we need to construct a way to map words that appear in the reviews to integers. Here we fix the size of our vocabulary (including the ‘no word’ and ‘infrequent’ categories) to be 5000 but we may wish to change this to see how it affects the model.
# determine the five most frequently appearing words in the training set.
word_dict = build_dict(train_X)
list(word_dict.keys())[0:5]
['movi', 'film', 'one', 'like', 'time']
Save word_dict
Later on when we construct an endpoint which processes a submitted review we will need to make use of the word_dict which we have created. As such, we will save it to a file now for future use.
data_dir = '../data/pytorch' # The folder we will use for storing data
if not os.path.exists(data_dir): # Make sure that the folder exists
os.makedirs(data_dir)
with open(os.path.join(data_dir, 'word_dict.pkl'), "wb") as f:
pickle.dump(word_dict, f)
Transform the reviews
Now that we have our word dictionary which allows us to transform the words appearing in the reviews into integers, it is time to make use of it and convert our reviews to their integer sequence representation, making sure to pad or truncate to a fixed length, which in our case is 500.
train_X, train_X_len = convert_and_pad_data(word_dict, train_X)
test_X, test_X_len = convert_and_pad_data(word_dict, test_X)
As a quick check to make sure that things are working as intended, check to see what one of the reviews in the training set looks like after having been processeed. Does this look reasonable? What is the length of a review in the training set?
# examine one of the processed reviews to make sure everything is working as intended.
print(train_X[100])
print('Length of train_X[100]: {}'.format(len(train_X[100])))
[ 4 1664 3614 1 2 4294 304 126 1 1 26 384 282 53
4476 1276 1721 955 69 105 161 26 6 16 1802 433 2007 1365
27 185 594 81 234 218 12 1664 3614 123 284 1 1 123
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
Length of train_X[100]: 500
preprocess_data function processed the raw data into something that is usable to the machine learning algorithm. It applies the review_to_words method to each of the reviews in training and testing dataset. So, it is necessary to avoid longer processing time when restarting the notebook. convert_and_pad_data function transformed the words appearing in the reviews into integer sequence representation. All the reviews are truncated to a fixed length, which is 500. Since LSTM classifier is used as the training algorithm, it is necessary to maintain a constant batch size during the training.
Step 3: Upload the data to S3
As in the XGBoost notebook, we will need to upload the training dataset to S3 in order for our training code to access it. For now we will save it locally and we will upload to S3 later on.
Save the processed training dataset locally
It is important to note the format of the data that we are saving as we will need to know it when we write the training code. In our case, each row of the dataset has the form label, length, review[500] where review[500] is a sequence of 500 integers representing the words in the review.
import pandas as pd
pd.concat([pd.DataFrame(train_y), pd.DataFrame(train_X_len),
pd.DataFrame(train_X)],
axis=1).to_csv(os.path.join(data_dir,'train.csv'),
header=False, index=False)
Uploading the training data
Next, we need to upload the training data to the SageMaker default S3 bucket so that we can provide access to it while training our model.
input_data = sagemaker_session.upload_data(path=data_dir, bucket=bucket,
key_prefix=prefix)
The cell above uploads the entire contents of our data directory. This includes the word_dict.pkl file. This is fortunate as we will need this later on when we create an endpoint that accepts an arbitrary review. For now, we will just take note of the fact that it resides in the data directory (and so also in the S3 training bucket) and that we will need to make sure it gets saved in the model directory.
Step 4: Build and Train the PyTorch Model
In the XGBoost notebook we discussed what a model is in the SageMaker framework. In particular, a model comprises three objects
- Model Artifacts,
- Training Code, and
- Inference Code,
each of which interact with one another. In the XGBoost example we used training and inference code that was provided by Amazon. Here we will still be using containers provided by Amazon with the added benefit of being able to include our own custom code.
We will start by implementing our own neural network in PyTorch along with a training script. For the purposes of this project we have provided the necessary model object in the model.py file, inside of the train folder. You can see the provided implementation by running the cell below.
!pygmentize train/model.py
[34mimport[39;49;00m [04m[36mtorch[39;49;00m[04m[36m.[39;49;00m[04m[36mnn[39;49;00m [34mas[39;49;00m [04m[36mnn[39;49;00m
[34mclass[39;49;00m [04m[32mLSTMClassifier[39;49;00m(nn.Module):
[33m"""[39;49;00m
[33m This is the simple RNN model we will be using to perform Sentiment Analysis.[39;49;00m
[33m """[39;49;00m
[34mdef[39;49;00m [32m__init__[39;49;00m([36mself[39;49;00m, embedding_dim, hidden_dim, vocab_size):
[33m"""[39;49;00m
[33m Initialize the model by settingg up the various layers.[39;49;00m
[33m """[39;49;00m
[36msuper[39;49;00m(LSTMClassifier, [36mself[39;49;00m).[32m__init__[39;49;00m()
[36mself[39;49;00m.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=[34m0[39;49;00m)
[36mself[39;49;00m.lstm = nn.LSTM(embedding_dim, hidden_dim)
[36mself[39;49;00m.dense = nn.Linear(in_features=hidden_dim, out_features=[34m1[39;49;00m)
[36mself[39;49;00m.sig = nn.Sigmoid()
[36mself[39;49;00m.word_dict = [34mNone[39;49;00m
[34mdef[39;49;00m [32mforward[39;49;00m([36mself[39;49;00m, x):
[33m"""[39;49;00m
[33m Perform a forward pass of our model on some input.[39;49;00m
[33m """[39;49;00m
x = x.t()
lengths = x[[34m0[39;49;00m,:]
reviews = x[[34m1[39;49;00m:,:]
embeds = [36mself[39;49;00m.embedding(reviews)
lstm_out, _ = [36mself[39;49;00m.lstm(embeds)
out = [36mself[39;49;00m.dense(lstm_out)
out = out[lengths - [34m1[39;49;00m, [36mrange[39;49;00m([36mlen[39;49;00m(lengths))]
[34mreturn[39;49;00m [36mself[39;49;00m.sig(out.squeeze())
The important takeaway from the implementation provided is that there are three parameters that we may wish to tweak to improve the performance of our model. These are the embedding dimension, the hidden dimension and the size of the vocabulary. We will likely want to make these parameters configurable in the training script so that if we wish to modify them we do not need to modify the script itself. We will see how to do this later on. To start we will write some of the training code in the notebook so that we can more easily diagnose any issues that arise.
First we will load a small portion of the training data set to use as a sample. It would be very time consuming to try and train the model completely in the notebook as we do not have access to a gpu and the compute instance that we are using is not particularly powerful. However, we can work on a small bit of the data to get a feel for how our training script is behaving.
# Read in only the first 250 rows
train_sample = pd.read_csv(os.path.join(data_dir, 'train.csv'),
header=None, names=None, nrows=250)
# Turn the input pandas dataframe into tensors
train_sample_y = torch.from_numpy(train_sample[[0]].values).float().squeeze()
train_sample_X = torch.from_numpy(train_sample.drop([0], axis=1).values).long()
# Build the dataset
train_sample_ds = torch.utils.data.TensorDataset(train_sample_X, train_sample_y)
# Build the dataloader
train_sample_dl = torch.utils.data.DataLoader(train_sample_ds, batch_size=50)
Writing the training method
Next we need to write the training code itself.
def train(model, train_loader, epochs, optimizer, loss_fn, device):
for epoch in range(1, epochs + 1):
model.train()
total_loss = 0
for batch in train_loader:
batch_X, batch_y = batch
batch_X = batch_X.to(device)
batch_y = batch_y.to(device)
# TODO: Complete this train method to train the model provided.
optimizer.zero_grad()
out = model(batch_X)
loss = loss_fn(out, batch_y)
loss.backward()
optimizer.step()
total_loss += loss.data.item()
print("Epoch: {}, BCELoss: {}".format(epoch, total_loss / len(train_loader)))
Supposing we have the training method above, we will test that it is working by writing a bit of code in the notebook that executes our training method on the small sample training set that we loaded earlier. The reason for doing this in the notebook is so that we have an opportunity to fix any errors that arise early when they are easier to diagnose.
import torch.optim as optim
from train.model import LSTMClassifier
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = LSTMClassifier(32, 100, 5000).to(device)
optimizer = optim.Adam(model.parameters())
loss_fn = torch.nn.BCELoss()
train(model, train_sample_dl, 5, optimizer, loss_fn, device)
Epoch: 1, BCELoss: 0.6928366303443909
Epoch: 2, BCELoss: 0.6814738273620605
Epoch: 3, BCELoss: 0.6727345705032348
Epoch: 4, BCELoss: 0.6641580820083618
Epoch: 5, BCELoss: 0.6548731803894043
In order to construct a PyTorch model using SageMaker we must provide SageMaker with a training script. We may optionally include a directory which will be copied to the container and from which our training code will be run. When the training container is executed it will check the uploaded directory (if there is one) for a requirements.txt file and install any required Python libraries, after which the training script will be run.
Training the model
from sagemaker.pytorch import PyTorch
estimator = PyTorch(entry_point="train.py",
source_dir="train",
role=role,
framework_version='0.4.0',
train_instance_count=1,
train_instance_type='ml.m4.xlarge',
hyperparameters={
'epochs': 10,
'hidden_dim': 200,
})
estimator.fit({'training': input_data})
'create_image_uri' will be deprecated in favor of 'ImageURIProvider' class in SageMaker Python SDK v2.
's3_input' class will be renamed to 'TrainingInput' in SageMaker Python SDK v2.
'create_image_uri' will be deprecated in favor of 'ImageURIProvider' class in SageMaker Python SDK v2.
2021-07-07 22:22:39 Starting - Starting the training job...
2021-07-07 22:22:41 Starting - Launching requested ML instances...
2021-07-07 22:23:32 Starting - Preparing the instances for training.........
2021-07-07 22:24:49 Downloading - Downloading input data...
2021-07-07 22:25:35 Training - Training image download completed. Training in progress..[34mbash: cannot set terminal process group (-1): Inappropriate ioctl for device[0m
[34mbash: no job control in this shell[0m
[34m2021-07-07 22:25:36,432 sagemaker-containers INFO Imported framework sagemaker_pytorch_container.training[0m
[34m2021-07-07 22:25:36,434 sagemaker-containers INFO No GPUs detected (normal if no gpus installed)[0m
[34m2021-07-07 22:25:36,448 sagemaker_pytorch_container.training INFO Block until all host DNS lookups succeed.[0m
[34m2021-07-07 22:25:39,484 sagemaker_pytorch_container.training INFO Invoking user training script.[0m
[34m2021-07-07 22:25:39,812 sagemaker-containers INFO Module train does not provide a setup.py. [0m
[34mGenerating setup.py[0m
[34m2021-07-07 22:25:39,813 sagemaker-containers INFO Generating setup.cfg[0m
[34m2021-07-07 22:25:39,813 sagemaker-containers INFO Generating MANIFEST.in[0m
[34m2021-07-07 22:25:39,813 sagemaker-containers INFO Installing module with the following command:[0m
[34m/usr/bin/python -m pip install -U . -r requirements.txt[0m
[34mProcessing /opt/ml/code[0m
[34mCollecting pandas (from -r requirements.txt (line 1))
Downloading https://files.pythonhosted.org/packages/74/24/0cdbf8907e1e3bc5a8da03345c23cbed7044330bb8f73bb12e711a640a00/pandas-0.24.2-cp35-cp35m-manylinux1_x86_64.whl (10.0MB)[0m
[34mCollecting numpy (from -r requirements.txt (line 2))[0m
[34m Downloading https://files.pythonhosted.org/packages/b5/36/88723426b4ff576809fec7d73594fe17a35c27f8d01f93637637a29ae25b/numpy-1.18.5-cp35-cp35m-manylinux1_x86_64.whl (19.9MB)[0m
[34mCollecting nltk (from -r requirements.txt (line 3))
Downloading https://files.pythonhosted.org/packages/5e/37/9532ddd4b1bbb619333d5708aaad9bf1742f051a664c3c6fa6632a105fd8/nltk-3.6.2-py3-none-any.whl (1.5MB)[0m
[34mCollecting beautifulsoup4 (from -r requirements.txt (line 4))
Downloading https://files.pythonhosted.org/packages/d1/41/e6495bd7d3781cee623ce23ea6ac73282a373088fcd0ddc809a047b18eae/beautifulsoup4-4.9.3-py3-none-any.whl (115kB)[0m
[34mCollecting html5lib (from -r requirements.txt (line 5))
Downloading https://files.pythonhosted.org/packages/6c/dd/a834df6482147d48e225a49515aabc28974ad5a4ca3215c18a882565b028/html5lib-1.1-py2.py3-none-any.whl (112kB)[0m
[34mCollecting pytz>=2011k (from pandas->-r requirements.txt (line 1))
Downloading https://files.pythonhosted.org/packages/70/94/784178ca5dd892a98f113cdd923372024dc04b8d40abe77ca76b5fb90ca6/pytz-2021.1-py2.py3-none-any.whl (510kB)[0m
[34mRequirement already satisfied, skipping upgrade: python-dateutil>=2.5.0 in /usr/local/lib/python3.5/dist-packages (from pandas->-r requirements.txt (line 1)) (2.7.5)[0m
[34mCollecting tqdm (from nltk->-r requirements.txt (line 3))[0m
[34m Downloading https://files.pythonhosted.org/packages/7a/ec/f8ff3ccfc4e59ce619a66a0bf29dc3b49c2e8c07de29d572e191c006eaa2/tqdm-4.61.2-py2.py3-none-any.whl (76kB)[0m
[34mRequirement already satisfied, skipping upgrade: click in /usr/local/lib/python3.5/dist-packages (from nltk->-r requirements.txt (line 3)) (7.0)[0m
[34mCollecting joblib (from nltk->-r requirements.txt (line 3))
Downloading https://files.pythonhosted.org/packages/28/5c/cf6a2b65a321c4a209efcdf64c2689efae2cb62661f8f6f4bb28547cf1bf/joblib-0.14.1-py2.py3-none-any.whl (294kB)[0m
[34mCollecting regex (from nltk->-r requirements.txt (line 3))
Downloading https://files.pythonhosted.org/packages/c0/d1/ad6afa6000ab869f6af2c85985d40558ffb298d9fcb2ab04c0648436008f/regex-2021.7.6.tar.gz (693kB)[0m
[34mCollecting soupsieve>1.2; python_version >= "3.0" (from beautifulsoup4->-r requirements.txt (line 4))
Downloading https://files.pythonhosted.org/packages/02/fb/1c65691a9aeb7bd6ac2aa505b84cb8b49ac29c976411c6ab3659425e045f/soupsieve-2.1-py3-none-any.whl[0m
[34mCollecting webencodings (from html5lib->-r requirements.txt (line 5))
Downloading https://files.pythonhosted.org/packages/f4/24/2a3e3df732393fed8b3ebf2ec078f05546de641fe1b667ee316ec1dcf3b7/webencodings-0.5.1-py2.py3-none-any.whl[0m
[34mRequirement already satisfied, skipping upgrade: six>=1.9 in /usr/local/lib/python3.5/dist-packages (from html5lib->-r requirements.txt (line 5)) (1.11.0)[0m
[34mBuilding wheels for collected packages: train, regex
Running setup.py bdist_wheel for train: started
Running setup.py bdist_wheel for train: finished with status 'done'
Stored in directory: /tmp/pip-ephem-wheel-cache-a6z07vb5/wheels/35/24/16/37574d11bf9bde50616c67372a334f94fa8356bc7164af8ca3
Running setup.py bdist_wheel for regex: started[0m
[34m Running setup.py bdist_wheel for regex: finished with status 'done'
Stored in directory: /root/.cache/pip/wheels/4d/21/94/ffc1c84ddb509f51dab71898a63df9fbff5f1e04552ee8ea8e[0m
[34mSuccessfully built train regex[0m
[34mInstalling collected packages: pytz, numpy, pandas, tqdm, joblib, regex, nltk, soupsieve, beautifulsoup4, webencodings, html5lib, train
Found existing installation: numpy 1.15.4
Uninstalling numpy-1.15.4:[0m
[34m Successfully uninstalled numpy-1.15.4[0m
[34mSuccessfully installed beautifulsoup4-4.9.3 html5lib-1.1 joblib-0.14.1 nltk-3.6.2 numpy-1.18.5 pandas-0.24.2 pytz-2021.1 regex-2021.7.6 soupsieve-2.1 tqdm-4.61.2 train-1.0.0 webencodings-0.5.1[0m
[34mYou are using pip version 18.1, however version 20.3.4 is available.[0m
[34mYou should consider upgrading via the 'pip install --upgrade pip' command.[0m
[34m2021-07-07 22:26:02,099 sagemaker-containers INFO No GPUs detected (normal if no gpus installed)[0m
[34m2021-07-07 22:26:02,126 sagemaker-containers INFO Invoking user script
[0m
[34mTraining Env:
[0m
[34m{
"output_data_dir": "/opt/ml/output/data",
"job_name": "sagemaker-pytorch-2021-07-07-22-22-39-625",
"additional_framework_parameters": {},
"output_intermediate_dir": "/opt/ml/output/intermediate",
"hosts": [
"algo-1"
],
"model_dir": "/opt/ml/model",
"user_entry_point": "train.py",
"input_dir": "/opt/ml/input",
"module_name": "train",
"module_dir": "s3://sagemaker-us-east-2-310177453216/sagemaker-pytorch-2021-07-07-22-22-39-625/source/sourcedir.tar.gz",
"num_cpus": 4,
"output_dir": "/opt/ml/output",
"log_level": 20,
"channel_input_dirs": {
"training": "/opt/ml/input/data/training"
},
"input_config_dir": "/opt/ml/input/config",
"num_gpus": 0,
"input_data_config": {
"training": {
"S3DistributionType": "FullyReplicated",
"RecordWrapperType": "None",
"TrainingInputMode": "File"
}
},
"resource_config": {
"hosts": [
"algo-1"
],
"current_host": "algo-1",
"network_interface_name": "eth0"
},
"network_interface_name": "eth0",
"hyperparameters": {
"hidden_dim": 200,
"epochs": 10
},
"framework_module": "sagemaker_pytorch_container.training:main",
"current_host": "algo-1"[0m
[34m}
[0m
[34mEnvironment variables:
[0m
[34mSM_NETWORK_INTERFACE_NAME=eth0[0m
[34mSM_INPUT_DATA_CONFIG={"training":{"RecordWrapperType":"None","S3DistributionType":"FullyReplicated","TrainingInputMode":"File"}}[0m
[34mSM_NUM_GPUS=0[0m
[34mSM_LOG_LEVEL=20[0m
[34mSM_CURRENT_HOST=algo-1[0m
[34mSM_MODULE_DIR=s3://sagemaker-us-east-2-310177453216/sagemaker-pytorch-2021-07-07-22-22-39-625/source/sourcedir.tar.gz[0m
[34mSM_FRAMEWORK_MODULE=sagemaker_pytorch_container.training:main[0m
[34mSM_HP_EPOCHS=10[0m
[34mSM_INPUT_CONFIG_DIR=/opt/ml/input/config[0m
[34mSM_HP_HIDDEN_DIM=200[0m
[34mSM_USER_ARGS=["--epochs","10","--hidden_dim","200"][0m
[34mSM_RESOURCE_CONFIG={"current_host":"algo-1","hosts":["algo-1"],"network_interface_name":"eth0"}[0m
[34mSM_NUM_CPUS=4[0m
[34mSM_OUTPUT_INTERMEDIATE_DIR=/opt/ml/output/intermediate[0m
[34mSM_TRAINING_ENV={"additional_framework_parameters":{},"channel_input_dirs":{"training":"/opt/ml/input/data/training"},"current_host":"algo-1","framework_module":"sagemaker_pytorch_container.training:main","hosts":["algo-1"],"hyperparameters":{"epochs":10,"hidden_dim":200},"input_config_dir":"/opt/ml/input/config","input_data_config":{"training":{"RecordWrapperType":"None","S3DistributionType":"FullyReplicated","TrainingInputMode":"File"}},"input_dir":"/opt/ml/input","job_name":"sagemaker-pytorch-2021-07-07-22-22-39-625","log_level":20,"model_dir":"/opt/ml/model","module_dir":"s3://sagemaker-us-east-2-310177453216/sagemaker-pytorch-2021-07-07-22-22-39-625/source/sourcedir.tar.gz","module_name":"train","network_interface_name":"eth0","num_cpus":4,"num_gpus":0,"output_data_dir":"/opt/ml/output/data","output_dir":"/opt/ml/output","output_intermediate_dir":"/opt/ml/output/intermediate","resource_config":{"current_host":"algo-1","hosts":["algo-1"],"network_interface_name":"eth0"},"user_entry_point":"train.py"}[0m
[34mSM_INPUT_DIR=/opt/ml/input[0m
[34mSM_CHANNEL_TRAINING=/opt/ml/input/data/training[0m
[34mSM_OUTPUT_DIR=/opt/ml/output[0m
[34mSM_USER_ENTRY_POINT=train.py[0m
[34mSM_OUTPUT_DATA_DIR=/opt/ml/output/data[0m
[34mSM_FRAMEWORK_PARAMS={}[0m
[34mPYTHONPATH=/usr/local/bin:/usr/lib/python35.zip:/usr/lib/python3.5:/usr/lib/python3.5/plat-x86_64-linux-gnu:/usr/lib/python3.5/lib-dynload:/usr/local/lib/python3.5/dist-packages:/usr/lib/python3/dist-packages[0m
[34mSM_MODEL_DIR=/opt/ml/model[0m
[34mSM_CHANNELS=["training"][0m
[34mSM_HOSTS=["algo-1"][0m
[34mSM_HPS={"epochs":10,"hidden_dim":200}[0m
[34mSM_MODULE_NAME=train
[0m
[34mInvoking script with the following command:
[0m
[34m/usr/bin/python -m train --epochs 10 --hidden_dim 200
[0m
[34mUsing device cpu.[0m
[34mGet train data loader.[0m
[34mModel loaded with embedding_dim 32, hidden_dim 200, vocab_size 5000.[0m
[34mEpoch: 1, BCELoss: 0.6779926054331721[0m
[34mEpoch: 2, BCELoss: 0.632936644310854[0m
[34mEpoch: 3, BCELoss: 0.5303341886218713[0m
[34mEpoch: 4, BCELoss: 0.45762525711740765[0m
[34mEpoch: 5, BCELoss: 0.39836534432002474[0m
[34mEpoch: 6, BCELoss: 0.3616019986113723[0m
[34mEpoch: 7, BCELoss: 0.34690997247793237[0m
[34mEpoch: 8, BCELoss: 0.32601447737946804[0m
[34mEpoch: 9, BCELoss: 0.300115918930696[0m
[34mEpoch: 10, BCELoss: 0.2793639363074789[0m
[34m2021-07-08 00:11:09,097 sagemaker-containers INFO Reporting training SUCCESS[0m
2021-07-08 00:11:55 Uploading - Uploading generated training model
2021-07-08 00:11:55 Completed - Training job completed
Training seconds: 6426
Billable seconds: 6426
Step 5: Testing the model
As mentioned at the top of this notebook, we will be testing this model by first deploying it and then sending the testing data to the deployed endpoint. We will do this so that we can make sure that the deployed model is working correctly.
Step 6: Deploy the model for testing
Now that we have trained our model, we would like to test it to see how it performs. Currently our model takes input of the form review_length, review[500] where review[500] is a sequence of 500 integers which describe the words present in the review, encoded using word_dict. Fortunately for us, SageMaker provides built-in inference code for models with simple inputs such as this.
There is one thing that we need to provide, however, and that is a function which loads the saved model. This function must be called model_fn() and takes as its only parameter a path to the directory where the model artifacts are stored. This function must also be present in the python file which we specified as the entry point. In our case the model loading function has been provided and so no changes need to be made.
Since we don’t need to change anything in the code that was uploaded during training, we can simply deploy the current model as-is.
# TODO: Deploy the trained model
predictor = estimator.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge')
-------------!
Step 7 - Use the model for testing
Once deployed, we can read in the test data and send it off to our deployed model to get some results. Once we collect all of the results we can determine how accurate our model is.
test_X = pd.concat([pd.DataFrame(test_X_len), pd.DataFrame(test_X)], axis=1)
# We split the data into chunks and send each chunk seperately, accumulating the results.
def predict(data, rows=512):
split_array = np.array_split(data, int(data.shape[0] / float(rows) + 1))
predictions = np.array([])
for array in split_array:
predictions = np.append(predictions, predictor.predict(array))
return predictions
predictions = predict(test_X.values)
predictions = [round(num) for num in predictions]
from sklearn.metrics import accuracy_score
accuracy_score(test_y, predictions)
0.82096
More testing
We now have a trained model which has been deployed and which we can send processed reviews to and which returns the predicted sentiment. However, ultimately we would like to be able to send our model an unprocessed review. That is, we would like to send the review itself as a string. For example, suppose we wish to send the following review to our model.
test_review = 'The simplest pleasures in life are the best, and this film is one of them. Combining a rather basic storyline of love and adventure this movie transcends the usual weekend fair with wit and unmitigated charm.'
The question we now need to answer is, how do we send this review to our model?
Recall in the first section of this notebook we did a bunch of data processing to the IMDb dataset. In particular, we did two specific things to the provided reviews.
- Removed any html tags and stemmed the input
- Encoded the review as a sequence of integers using
word_dict
In order process the review we will need to repeat these two steps.
Using the review_to_words and convert_and_pad methods from section one, convert test_review into a numpy array test_data suitable to send to our model. Remember that our model expects input of the form review_length, review[500].
# Convert test_review into a form usable by the model and save the results in test_data
test_review_words = review_to_words(test_review) # splits reviews to words
review_X, review_len = convert_and_pad(word_dict, test_review_words) # pad review
data_pack = np.hstack((review_len, review_X))
data_pack = data_pack.reshape(1, -1)
test_data = torch.from_numpy(data_pack)
test_data = test_data.to(device)
Now that we have processed the review, we can send the resulting array to our model to predict the sentiment of the review.
predictor.predict(test_data)
array(0.8274373, dtype=float32)
Since the return value of our model is close to 1, we can be certain that the review we submitted is positive.
Delete the endpoint
Of course, just like in the XGBoost notebook, once we’ve deployed an endpoint it continues to run until we tell it to shut down. Since we are done using our endpoint for now, we can delete it.
estimator.delete_endpoint()
estimator.delete_endpoint() will be deprecated in SageMaker Python SDK v2. Please use the delete_endpoint() function on your predictor instead.
Step 6 (again) - Deploy the model for the web app
Now that we know that our model is working, it’s time to create some custom inference code so that we can send the model a review which has not been processed and have it determine the sentiment of the review.
As we saw above, by default the estimator which we created, when deployed, will use the entry script and directory which we provided when creating the model. However, since we now wish to accept a string as input and our model expects a processed review, we need to write some custom inference code.
We will store the code that we write in the serve directory. Provided in this directory is the model.py file that we used to construct our model, a utils.py file which contains the review_to_words and convert_and_pad pre-processing functions which we used during the initial data processing, and predict.py, the file which will contain our custom inference code. Note also that requirements.txt is present which will tell SageMaker what Python libraries are required by our custom inference code.
When deploying a PyTorch model in SageMaker, you are expected to provide four functions which the SageMaker inference container will use.
model_fn: This function is the same function that we used in the training script and it tells SageMaker how to load our model.input_fn: This function receives the raw serialized input that has been sent to the model’s endpoint and its job is to de-serialize and make the input available for the inference code.output_fn: This function takes the output of the inference code and its job is to serialize this output and return it to the caller of the model’s endpoint.predict_fn: The heart of the inference script, this is where the actual prediction is done and is the function which you will need to complete.
For the simple website that we are constructing during this project, the input_fn and output_fn methods are relatively straightforward. We only require being able to accept a string as input and we expect to return a single value as output. You might imagine though that in a more complex application the input or output may be image data or some other binary data which would require some effort to serialize.
Writing inference code
Before writing our custom inference code, we will begin by taking a look at the code which has been provided.
!pygmentize serve/predict.py
[34mimport[39;49;00m [04m[36margparse[39;49;00m
[34mimport[39;49;00m [04m[36mjson[39;49;00m
[34mimport[39;49;00m [04m[36mos[39;49;00m
[34mimport[39;49;00m [04m[36mpickle[39;49;00m
[34mimport[39;49;00m [04m[36msys[39;49;00m
[34mimport[39;49;00m [04m[36msagemaker_containers[39;49;00m
[34mimport[39;49;00m [04m[36mpandas[39;49;00m [34mas[39;49;00m [04m[36mpd[39;49;00m
[34mimport[39;49;00m [04m[36mnumpy[39;49;00m [34mas[39;49;00m [04m[36mnp[39;49;00m
[34mimport[39;49;00m [04m[36mtorch[39;49;00m
[34mimport[39;49;00m [04m[36mtorch[39;49;00m[04m[36m.[39;49;00m[04m[36mnn[39;49;00m [34mas[39;49;00m [04m[36mnn[39;49;00m
[34mimport[39;49;00m [04m[36mtorch[39;49;00m[04m[36m.[39;49;00m[04m[36moptim[39;49;00m [34mas[39;49;00m [04m[36moptim[39;49;00m
[34mimport[39;49;00m [04m[36mtorch[39;49;00m[04m[36m.[39;49;00m[04m[36mutils[39;49;00m[04m[36m.[39;49;00m[04m[36mdata[39;49;00m
[34mfrom[39;49;00m [04m[36mmodel[39;49;00m [34mimport[39;49;00m LSTMClassifier
[34mfrom[39;49;00m [04m[36mutils[39;49;00m [34mimport[39;49;00m review_to_words, convert_and_pad
[34mdef[39;49;00m [32mmodel_fn[39;49;00m(model_dir):
[33m"""Load the PyTorch model from the `model_dir` directory."""[39;49;00m
[36mprint[39;49;00m([33m"[39;49;00m[33mLoading model.[39;49;00m[33m"[39;49;00m)
[37m# First, load the parameters used to create the model.[39;49;00m
model_info = {}
model_info_path = os.path.join(model_dir, [33m'[39;49;00m[33mmodel_info.pth[39;49;00m[33m'[39;49;00m)
[34mwith[39;49;00m [36mopen[39;49;00m(model_info_path, [33m'[39;49;00m[33mrb[39;49;00m[33m'[39;49;00m) [34mas[39;49;00m f:
model_info = torch.load(f)
[36mprint[39;49;00m([33m"[39;49;00m[33mmodel_info: [39;49;00m[33m{}[39;49;00m[33m"[39;49;00m.format(model_info))
[37m# Determine the device and construct the model.[39;49;00m
device = torch.device([33m"[39;49;00m[33mcuda[39;49;00m[33m"[39;49;00m [34mif[39;49;00m torch.cuda.is_available() [34melse[39;49;00m [33m"[39;49;00m[33mcpu[39;49;00m[33m"[39;49;00m)
model = LSTMClassifier(model_info[[33m'[39;49;00m[33membedding_dim[39;49;00m[33m'[39;49;00m], model_info[[33m'[39;49;00m[33mhidden_dim[39;49;00m[33m'[39;49;00m], model_info[[33m'[39;49;00m[33mvocab_size[39;49;00m[33m'[39;49;00m])
[37m# Load the store model parameters.[39;49;00m
model_path = os.path.join(model_dir, [33m'[39;49;00m[33mmodel.pth[39;49;00m[33m'[39;49;00m)
[34mwith[39;49;00m [36mopen[39;49;00m(model_path, [33m'[39;49;00m[33mrb[39;49;00m[33m'[39;49;00m) [34mas[39;49;00m f:
model.load_state_dict(torch.load(f))
[37m# Load the saved word_dict.[39;49;00m
word_dict_path = os.path.join(model_dir, [33m'[39;49;00m[33mword_dict.pkl[39;49;00m[33m'[39;49;00m)
[34mwith[39;49;00m [36mopen[39;49;00m(word_dict_path, [33m'[39;49;00m[33mrb[39;49;00m[33m'[39;49;00m) [34mas[39;49;00m f:
model.word_dict = pickle.load(f)
model.to(device).eval()
[36mprint[39;49;00m([33m"[39;49;00m[33mDone loading model.[39;49;00m[33m"[39;49;00m)
[34mreturn[39;49;00m model
[34mdef[39;49;00m [32minput_fn[39;49;00m(serialized_input_data, content_type):
[36mprint[39;49;00m([33m'[39;49;00m[33mDeserializing the input data.[39;49;00m[33m'[39;49;00m)
[34mif[39;49;00m content_type == [33m'[39;49;00m[33mtext/plain[39;49;00m[33m'[39;49;00m:
data = serialized_input_data.decode([33m'[39;49;00m[33mutf-8[39;49;00m[33m'[39;49;00m)
[34mreturn[39;49;00m data
[34mraise[39;49;00m [36mException[39;49;00m([33m'[39;49;00m[33mRequested unsupported ContentType in content_type: [39;49;00m[33m'[39;49;00m + content_type)
[34mdef[39;49;00m [32moutput_fn[39;49;00m(prediction_output, accept):
[36mprint[39;49;00m([33m'[39;49;00m[33mSerializing the generated output.[39;49;00m[33m'[39;49;00m)
[34mreturn[39;49;00m [36mstr[39;49;00m(prediction_output)
[34mdef[39;49;00m [32mpredict_fn[39;49;00m(input_data, model):
[36mprint[39;49;00m([33m'[39;49;00m[33mInferring sentiment of input data.[39;49;00m[33m'[39;49;00m)
device = torch.device([33m"[39;49;00m[33mcuda[39;49;00m[33m"[39;49;00m [34mif[39;49;00m torch.cuda.is_available() [34melse[39;49;00m [33m"[39;49;00m[33mcpu[39;49;00m[33m"[39;49;00m)
[34mif[39;49;00m model.word_dict [35mis[39;49;00m [34mNone[39;49;00m:
[34mraise[39;49;00m [36mException[39;49;00m([33m'[39;49;00m[33mModel has not been loaded properly, no word_dict.[39;49;00m[33m'[39;49;00m)
[37m# TODO: Process input_data so that it is ready to be sent to our model.[39;49;00m
[37m# You should produce two variables:[39;49;00m
[37m# data_X - A sequence of length 500 which represents the converted review[39;49;00m
[37m# data_len - The length of the review[39;49;00m
[37m#word = review_to_words(input_data)[39;49;00m
[37m#data_X, data_len = convert_and_pad(model.word_dict, word)[39;49;00m
data_X, data_len = convert_and_pad(model.word_dict, np.array(review_to_words(input_data)))
[37m# Using data_X and data_len we construct an appropriate input tensor. Remember[39;49;00m
[37m# that our model expects input data of the form 'len, review[500]'.[39;49;00m
data_pack = np.hstack((data_len, data_X))
data_pack = data_pack.reshape([34m1[39;49;00m, -[34m1[39;49;00m)
data = torch.from_numpy(data_pack)
data = data.to(device)
[37m# Make sure to put the model into evaluation mode[39;49;00m
model.eval()
[37m# TODO: Compute the result of applying the model to the input data. The variable `result` should[39;49;00m
[37m# be a numpy array which contains a single integer which is either 1 or 0[39;49;00m
[37m#with torch.no_grad():[39;49;00m
[37m# out = model.forward(data)[39;49;00m
[37m#result = np.round(out.numpy())[39;49;00m
out = model(data).detach().cpu().numpy()
[36mprint[39;49;00m(out)
result = np.round(out).astype(np.int)
[34mreturn[39;49;00m result
As mentioned earlier, the model_fn method is the same as the one provided in the training code and the input_fn and output_fn methods are very simple and your task will be to complete the predict_fn method.
Deploying the model
Now that the custom inference code has been written, we will create and deploy our model. To begin with, we need to construct a new PyTorchModel object which points to the model artifacts created during training and also points to the inference code that we wish to use. Then we can call the deploy method to launch the deployment container.
from sagemaker.predictor import RealTimePredictor
from sagemaker.pytorch import PyTorchModel
class StringPredictor(RealTimePredictor):
def __init__(self, endpoint_name, sagemaker_session):
super(StringPredictor, self).__init__(endpoint_name, sagemaker_session, content_type='text/plain')
model = PyTorchModel(model_data=estimator.model_data,
role = role,
framework_version='0.4.0',
entry_point='predict.py',
source_dir='serve',
predictor_cls=StringPredictor)
predictor = model.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge')
Parameter image will be renamed to image_uri in SageMaker Python SDK v2.
'create_image_uri' will be deprecated in favor of 'ImageURIProvider' class in SageMaker Python SDK v2.
-------------!
Testing the model
Now that we have deployed our model with the custom inference code, we should test to see if everything is working. Here we test our model by loading the first 250 positive and negative reviews and send them to the endpoint, then collect the results. The reason for only sending some of the data is that the amount of time it takes for our model to process the input and then perform inference is quite long and so testing the entire data set would be prohibitive.
ground, results = test_reviews()
Starting pos files
Starting neg files
from sklearn.metrics import accuracy_score
accuracy_score(ground, results)
0.83
As an additional test, we can try sending the test_review that we looked at earlier.
predictor.predict(test_review)
b'1'
Now that we know our endpoint is working as expected, we can set up the web page that will interact with it.
Step 7 (again): Use the model for the web app
This entire section and the next contain tasks to complete, mostly using the AWS console.
So far we have been accessing our model endpoint by constructing a predictor object which uses the endpoint and then just using the predictor object to perform inference. What if we wanted to create a web app which accessed our model? The way things are set up currently makes that not possible since in order to access a SageMaker endpoint the app would first have to authenticate with AWS using an IAM role which included access to SageMaker endpoints. However, there is an easier way! We just need to use some additional AWS services.

The diagram above gives an overview of how the various services will work together. On the far right is the model which we trained above and which is deployed using SageMaker. On the far left is our web app that collects a user’s movie review, sends it off and expects a positive or negative sentiment in return.
In the middle is where some of the magic happens. We will construct a Lambda function, which you can think of as a straightforward Python function that can be executed whenever a specified event occurs. We will give this function permission to send and recieve data from a SageMaker endpoint.
Lastly, the method we will use to execute the Lambda function is a new endpoint that we will create using API Gateway. This endpoint will be a url that listens for data to be sent to it. Once it gets some data it will pass that data on to the Lambda function and then return whatever the Lambda function returns. Essentially it will act as an interface that lets our web app communicate with the Lambda function.
Setting up a Lambda function
Part A: Create an IAM Role for the Lambda function
Part B: Create a Lambda function
# We need to use the low-level library to interact with SageMaker since the SageMaker API
# is not available natively through Lambda.
import boto3
def lambda_handler(event, context):
# The SageMaker runtime is what allows us to invoke the endpoint that we've created.
runtime = boto3.Session().client('sagemaker-runtime')
# Now we use the SageMaker runtime to invoke our endpoint, sending the review we were given
response = runtime.invoke_endpoint(EndpointName = '**ENDPOINT NAME HERE**', # The name of the endpoint we created
ContentType = 'text/plain', # The data format that is expected
Body = event['body']) # The actual review
# The response is an HTTP response whose body contains the result of our inference
result = response['Body'].read().decode('utf-8')
return {
'statusCode' : 200,
'headers' : { 'Content-Type' : 'text/plain', 'Access-Control-Allow-Origin' : '*' },
'body' : result
}
predictor.endpoint
'sagemaker-pytorch-2021-07-08-00-33-55-659'
Step 4: Deploying our web app